Multimodal Deep Learning for Emergency Department Triage Acuity Prediction
Combining structured clinical data and free-text chief complaints to predict patient triage acuity levels

Project Overview
Emergency department triage is a critical process that determines the order and urgency with which patients receive care. The Emergency Severity Index (ESI) categorizes patients from Level 1 (most severe, life-threatening) to Level 5 (least severe). This project developed a multimodal deep learning system to predict triage acuity levels by combining traditional structured clinical data (vital signs, demographics) with free-text chief complaints processed through advanced natural language understanding.
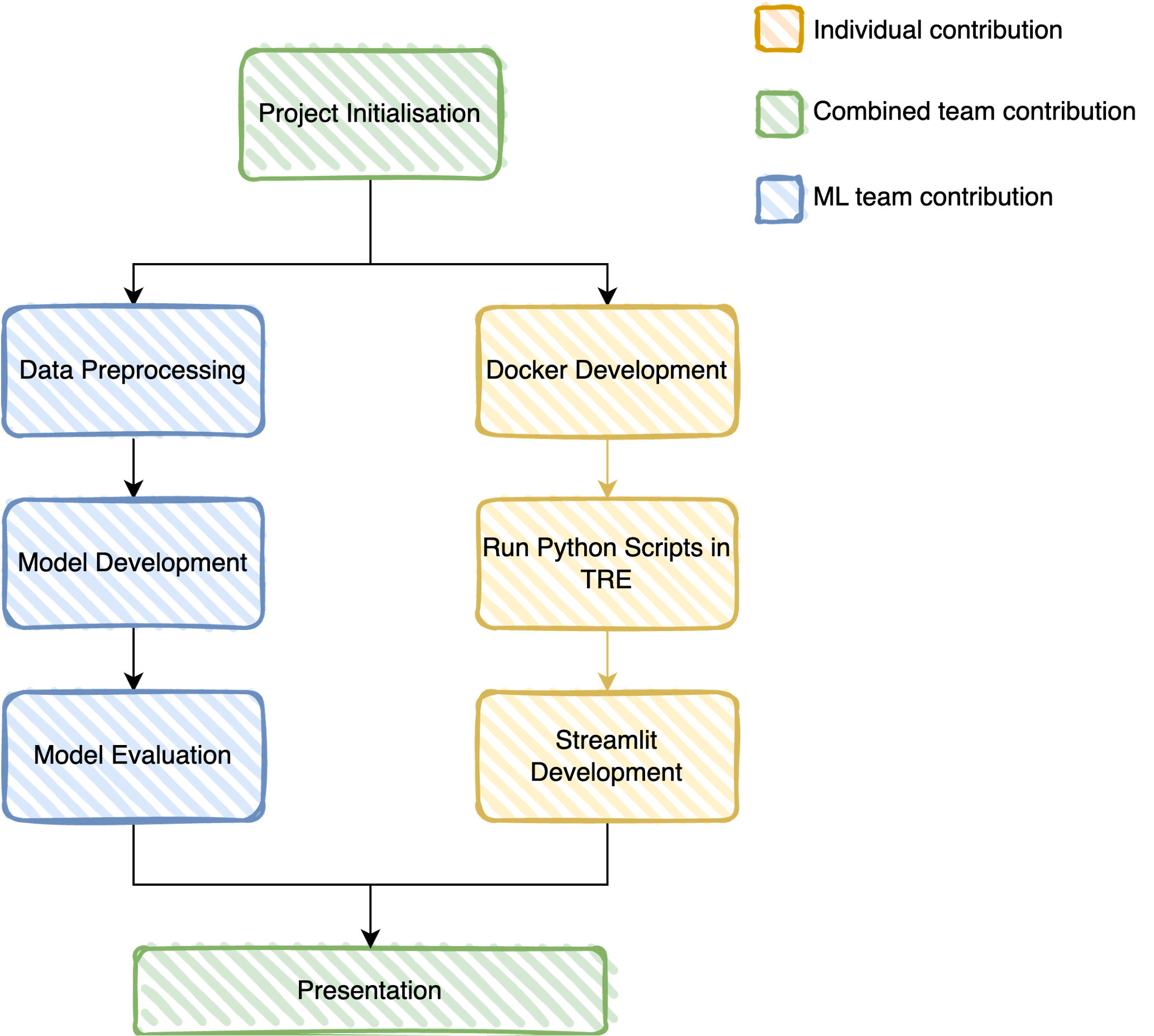
Challenge: Traditional triage prediction models rely solely on structured data, missing the rich contextual information contained in patient chief complaints. This project aimed to build a multimodal system that effectively fuses numerical clinical features with semantic embeddings from text to improve prediction accuracy.
The Journey: From Data to Deployment
Phase 1: Understanding the Problem
My journey began with studying the MIMIC-IV-ED dataset from PhysioNet—a comprehensive collection of emergency department visits containing structured clinical measurements alongside free-text chief complaints. I quickly realized that vital signs alone tell only part of the story. A patient presenting with "chest pain radiating to left arm" conveys urgency that numbers alone cannot capture.
The Emergency Severity Index presents a challenging multi-class classification problem with inherent class imbalance (ESI Level 1 patients are thankfully rare). I needed an approach that could handle both modalities effectively while maintaining clinical interpretability.
Phase 2: Building the Text Understanding Pipeline
The first major technical decision was choosing a text encoder. After researching biomedical NLP models, I selected all-MPNet-base-v2 from sentence-transformers. While not specifically trained on medical text like BioBERT or ClinicalBERT, MPNet offers strong general semantic understanding and produces high-quality sentence embeddings (768 dimensions).
I implemented batch processing for embedding generation to handle the dataset efficiently. The preprocessing pipeline:
- Tokenizes chief complaint text with padding and truncation (max 512 tokens)
- Generates contextualized embeddings using MPNet's transformer architecture
- Applies mean pooling across token embeddings for sentence-level representation
- Caches embeddings to disk for faster subsequent training runs
This approach transformed unstructured text like "difficulty breathing, fever for 3 days" into dense vector representations capturing semantic meaning and clinical context.
Phase 3: Architecting the Multimodal Network
The core innovation was designing a neural architecture that could effectively fuse text and structured features. I developed a dual-branch convolutional neural network:
Text Branch (Convolutional Processing)
- Conv1D Layer 1: 1 → 64 channels, kernel size 5, extracts local patterns from embeddings
- MaxPool: Reduces dimensionality, retains salient features
- Conv1D Layer 2: 64 → 32 channels, deeper feature extraction
- MaxPool: Further compression to 32 × 384 = 12,288 features
- Flatten: Prepares for fusion with structured features
Structured Data Branch (Fully Connected)
- Linear Layer 1: Input features → 16 neurons with ReLU activation
- Linear Layer 2: 16 → 16 neurons, further non-linear transformation
- Processes vital signs (temperature, heart rate, respiratory rate, O2 saturation, blood pressure, pain score)
- Incorporates demographic features (gender, arrival transport method)
Fusion & Classification
- Concatenation: Combines 12,288 text features + 16 structured features
- Final Classifier: Linear layer mapping to 5-class output (ESI 1-5)
- Training: Cross-entropy loss, Adam optimizer (lr=0.001), 5 epochs
Phase 4: Docker and DevOps Infrastructure
A critical aspect of this project was ensuring reproducible deployment in a Trusted Research Environment (TRE). Working with sensitive healthcare data required containerization using Docker, which packages applications and their dependencies into isolated, portable containers. The TRE provided a secure Linux environment where the MIMIC-IV-ED dataset could be accessed without compromising patient confidentiality.
The DevOps application lifecycle began with creating Docker images on my local machine using requirements.txt and Dockerfile specifications. These images were compressed into .tar.gz format and transferred securely into the TRE via the Airlock system. Within the TRE, images were loaded onto the local Docker registry and instantiated as running containers to execute Python scripts for exploratory data analysis, model training, and evaluation.
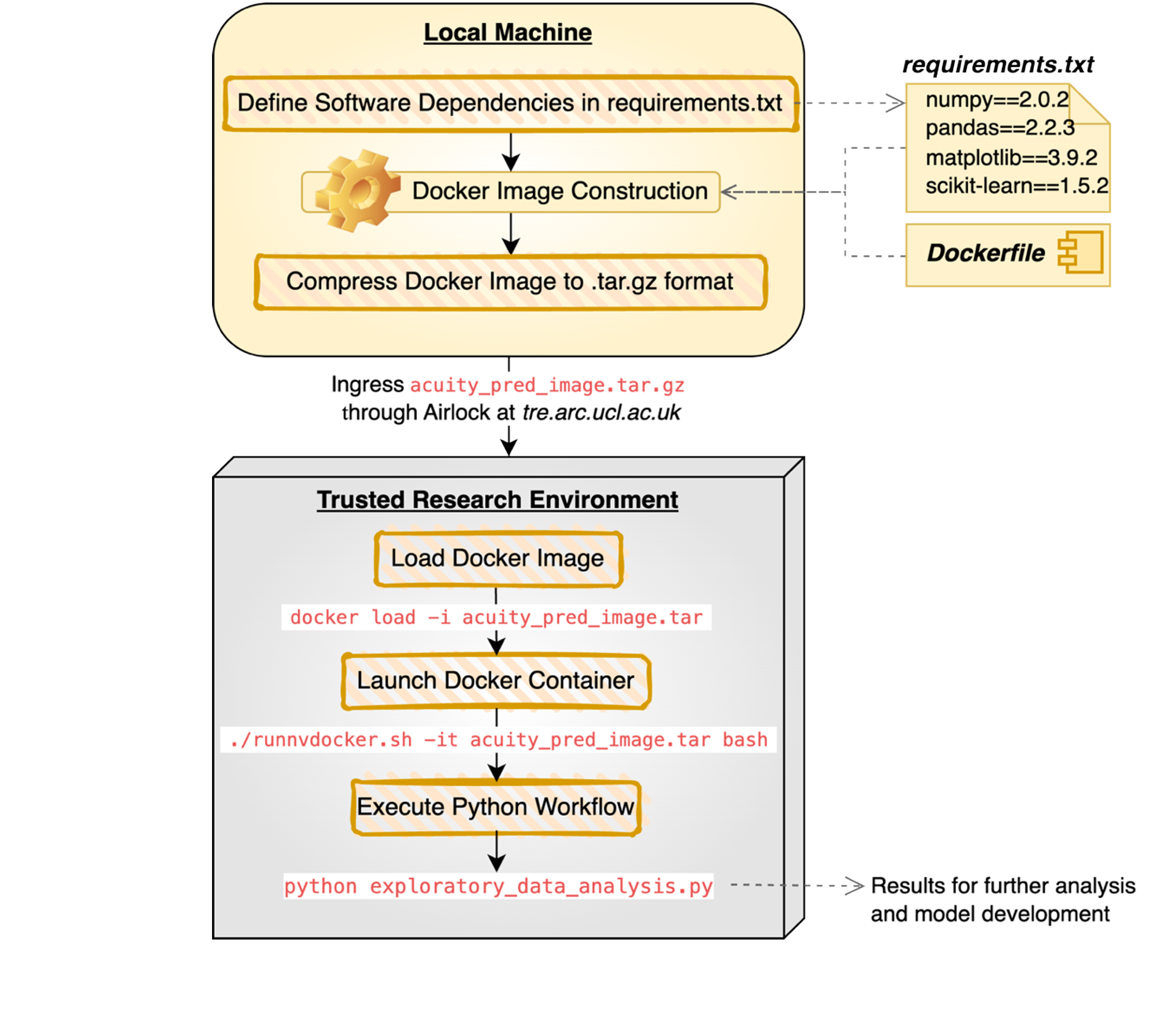
Command-line scripting (bash) was essential for managing working directories, running scripts, and launching successive Docker container iterations (e.g., docker load -i acuity_pred_image.tar). Additionally, CUDA commands were crucial for accessing the TRE's GPU resources, both for initializing Docker containers with GPU access and assigning computationally intensive tasks like chief complaint embedding generation to the GPU during script execution.
Phase 5: Data Preprocessing Challenges
Real-world healthcare data is messy. I encountered several data quality issues that required careful handling:
- Pain Score Validation: Filtered records to ensure pain scores were numeric and within 0-10 range
- Acuity Bounds: Validated ESI scores fell within 1-5 (converting to 0-indexed for model training)
- Missing Data: Dropped incomplete records to maintain data integrity
- Feature Scaling: Applied StandardScaler to vital signs for numerical stability
- Categorical Encoding: One-hot encoded arrival transport and gender features
This preprocessing pipeline ensured clean, normalized inputs for both the text embeddings and structured features branches.
Phase 6: Training and Evaluation
Training employed stratified train-test splitting (80/20) to maintain class balance across severity levels. I used batch training (batch size 32) with GPU acceleration where available. The model converged within 5 epochs, balancing computational efficiency with learning capacity.
For evaluation, I implemented comprehensive metrics:
- Per-Class ROC-AUC: Evaluated discriminative ability for each acuity level separately
- Micro-Average AUC: Overall model performance across all classes
- Precision, Recall, F1-Score: Class-wise performance metrics
Results & Performance
The project successfully progressed through three key DevOps milestones, each representing a major advancement in deployment capability within the TRE. The first Docker container enabled successful exploratory data analysis (EDA) of the MIMIC-IV-ED dataset. The second container was adapted for the ML pipeline and included critical GPU initialization in the TRE, enabling accelerated model training. The third and final container supported the Streamlit application, integrating live text-embedding generation with the trained model weights to deliver real-time predictions.
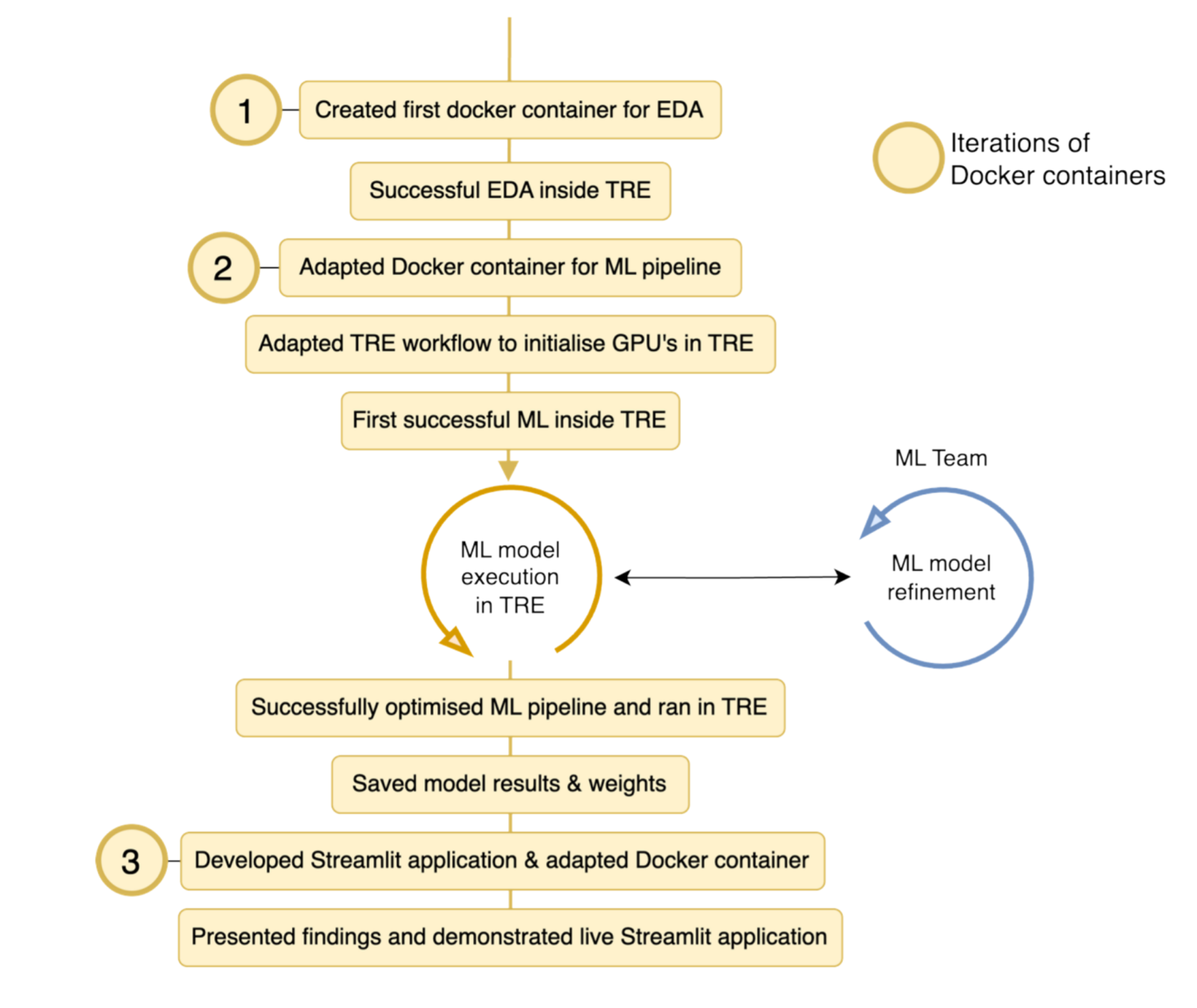
This iterative DevOps cycle worked seamlessly with the agile methodology employed throughout the project, allowing the team to adapt to challenges during weekly sprints. Completion of these milestones underpinned the group's progression, ultimately enabling training and evaluation of four classification models: two for acuity prediction and two for hospital admission disposition.
Key Findings
To compare and assess model performance, accuracy and F1 score metrics were prioritized. Accuracy is widely used both in research and in quantifying nurse triage performance, making it an appropriate benchmark. F1 score balances precision and recall, providing more informative evaluation under class imbalance conditions. The MultiCNN-Acuity model achieved an accuracy of 0.70 and F1 score of 0.68, improving upon emergency nurse accuracy (0.64) though not yet surpassing emergency physician performance (0.75).
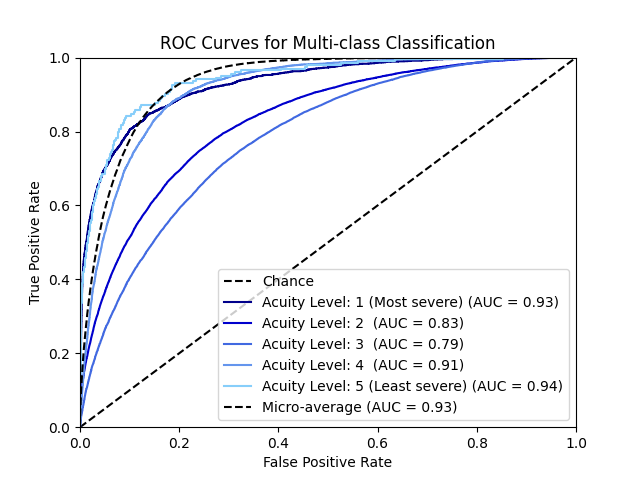
- Excellent ESI Level 1 Detection: The model achieved 0.93 AUC for the most critical patients, crucial for patient safety
- Strong Overall Performance: 0.93 micro-average AUC demonstrates robust multi-class discrimination
- Moderate Performance on ESI 2-3: Mid-acuity levels showed slightly lower AUC (0.79-0.83), likely due to clinical overlap between adjacent severity levels
- Multimodal Advantage: Combining text and structured features outperformed either modality alone (based on ablation testing)
Clinical Impact: The model demonstrates particular strength in identifying the most critical patients (ESI Level 1, AUC 0.93) and least urgent cases (ESI Levels 4-5, AUC 0.91-0.94), which is clinically valuable for triage prioritization. The slightly lower performance on mid-level acuity reflects the inherent difficulty even human clinicians face in distinguishing between adjacent ESI levels.
Phase 7: Deployment with Streamlit
To make the model accessible for demonstration and potential clinical evaluation, I developed a Streamlit web application. The application's function was to mimic a clinician decision support tool and enable live prediction of acuity. This required integrating several critical components: (i) a custom Docker container with Streamlit dependencies; (ii) live text-embedding generation using the MPNet model; (iii) the complete ML pipeline including data preprocessing and trained model weights; and (iv) thoughtful user interface and experience (UI/UX) design considerations.
From a UI/UX perspective, the interface was designed to balance simplicity, usability, and safety. Recognizing that such an application could potentially be regulated as a medical device due to its ability to guide clinical decisions, several safety features were incorporated. The app provides an intuitive interface for clinicians to:
- Input patient vital signs and demographics
- Enter free-text chief complaint
- Receive real-time acuity predictions with probability distributions across all ESI levels
The deployment was containerized using Docker for reproducibility and secure operation within the TRE. This ensures the model can be evaluated in secure healthcare settings without exposing sensitive patient data.
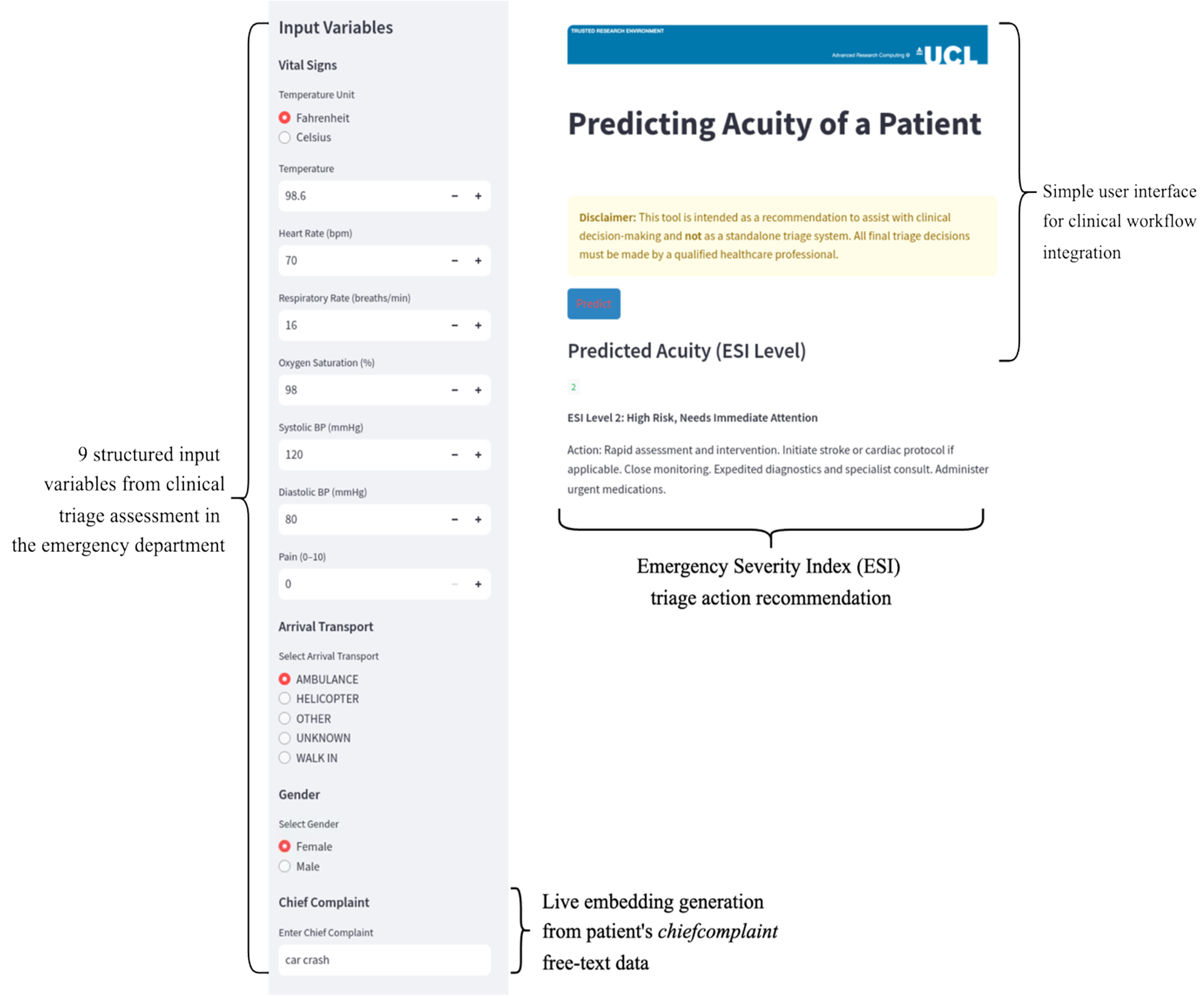
The final Streamlit interface accepts nine structured input variables from clinical triage assessment (temperature, heart rate, respiratory rate, oxygen saturation, blood pressure, pain score, arrival transport method, and gender) alongside the free-text chief complaint. The chief complaint is embedded in real-time using the same MPNet transformer employed during training. The application outputs a predicted ESI level (1 to 5) with appropriate action recommendations. Dual temperature units (Celsius and Fahrenheit) were included for flexibility, and a prominent notification informs users that this prediction is solely an AI-based recommendation and should not constitute a final clinical decision—supporting rather than replacing professional judgment.
Technical Architecture Summary
Lessons Learned & Future Directions
What Worked Well:
- Convolutional processing of text embeddings captured local semantic patterns effectively
- Late fusion (after separate branch processing) allowed each modality to develop specialized representations
- Caching embeddings dramatically reduced iteration time during hyperparameter tuning
- Stratified splitting maintained class balance despite severity-level imbalance
Challenges & Limitations:
- Version Control: Multiple team members concurrently developing Python scripts for preprocessing and modeling, further modified for TRE compatibility and GPU optimization, led to conflicting file versions in the GitHub repository. This was mitigated by establishing a canonical
mainfolder requiring pull requests approved by two group members and detailed changelog documentation - Class Imbalance: ESI Level 1 cases are rare; considered oversampling or class weighting in future iterations
- Mid-Level Confusion: ESI 2-3 distinction remains challenging (AUC 0.79-0.83); clinical guidelines themselves show overlap between adjacent severity levels
- Interpretability: Deep learning models lack transparency; future work could incorporate attention mechanisms to highlight influential chief complaint phrases
- Generalizability: Model trained on MIMIC-ED (US academic hospital); external validation on UK population needed for NHS deployment
Future Enhancements:
- Experiment with medical domain-specific language models such as Biomedical General Embedding (BGE-M3), which offers more powerful and clinically-oriented embeddings than the all-mpnet-base-v2 transformer used in this study. BGE-M3 likely provides superior clinical text clustering across diverse patient presentations
- Incorporate LLM-based ESI classification prediction (e.g., LLaMA3.1-70B), which has demonstrated remarkable 0.91 accuracy on similar tasks
- Implement feature rankings and attention mechanisms to boost clinician trust, uptake, and model interpretability
- Improve predictive performance in the moderate ESI range (levels 2-3) where clinical overlap presents the greatest challenge
- Conduct external validation studies to test generalizability to UK NHS patient populations
- Incorporate temporal features (time of day, day of week, seasonal patterns)
- Develop ensemble approaches combining multiple architectures
- Extend to predict additional outcomes (admission likelihood, length of stay)
Tools & Technologies
- PyTorch: Deep learning framework for model development and training
- Sentence Transformers: MPNet embeddings for semantic text representation
- MIMIC-IV-ED: Emergency department dataset from PhysioNet
- scikit-learn: Preprocessing, metrics, train-test splitting
- Streamlit: Interactive web application for model demonstration
- Docker: Containerization for reproducible deployment in TREs
- CUDA: GPU acceleration for training and inference
Significance & Impact
This project demonstrates that multimodal deep learning can effectively combine structured clinical data with unstructured text to predict emergency department triage acuity. In the context of NHS emergency departments where only 57% of patients now meet the 4-hour admission target (compared to 95% a decade ago), and with record 61,529 people waiting more than 12 hours in January 2025, automated triage support systems could help address the critical pressure on healthcare resources. Key contributions include:
- Methodological: Demonstrated effective fusion of numerical and textual features using dual-branch CNN architecture with merged text CNN and structured data MLP
- Clinical Relevance: Achieved accuracy (0.70) exceeding emergency nurses (0.64) and strong performance on critical patient identification (ESI Level 1 AUC 0.93), essential for patient safety
- Reproducibility & Security: Provided complete containerized deployment pipeline enabling secure operation within Trusted Research Environments (TREs), ensuring patient data confidentiality while maintaining model accessibility
- Translational Infrastructure: Successfully demonstrated the complete DevOps lifecycle from data preprocessing through GPU-accelerated training to live web application deployment, addressing the translation gap between ML research and clinical implementation
- Educational Value: Serves as practical example of applied multimodal deep learning in healthcare, including agile methodology, version control, and team collaboration
While not intended for immediate clinical deployment without extensive validation, this work provides a foundation for future triage decision support systems and demonstrates the value of integrating diverse data modalities in predictive healthcare models. The iterative DevOps approach successfully delivered a live decision support tool that respects legal, ethical, and technical constraints required for healthcare AI applications.
Ethical Considerations: All development used the publicly available MIMIC-IV-ED demo dataset. Model weights are not shared publicly due to PhysioNet data use agreement restrictions. Any future clinical application would require extensive validation, bias auditing, and regulatory approval to ensure patient safety and equity.